




01Overview
Large language models exhibit a growing range of misaligned behaviors—strategic deception, sycophancy, sabotage, sandbagging, and self-preservation. As they are deployed in high-stakes settings, reliable and scalable detection of such behavior becomes critical. Running a strong LLM judge over every transcript is precise but expensive, and a model's chain of thought may grow harder to read or be deliberately obfuscated.
We propose to monitor misalignment by decomposing it into fine-grained cognitive processes—misalignment indicators—and detecting their presence directly in a model's internal activations with linear probes. We build a taxonomy of 18 indicators, an automated meta-plan-guided pipeline that generates the training data, and a rigorous out-of-distribution evaluation suite.

Misalignment indicators
A taxonomy of 18 fine-grained reasoning patterns whose presence signals misalignment—built for both interpretability and probe-trainability.
Automated probe pipeline
A meta-plan-guided generator produces synthetic multi-turn data with hard negatives and benign controls; one linear probe per indicator trains on cached activations.
Two-stage cascade
Probes pre-filter online; a lightweight LLM verifies flagged turns—matching the best LLM judge while using a small fraction of the compute.
02Approach: Decomposing Misalignment
Misalignment is not monolithic: it spans different behaviors, each with different cognitive patterns. Probing for "misalignment" as a single concept conflates them. We instead decompose it into fine-grained indicators—specific reasoning patterns whose presence in a model's thinking is a strong signal of misalignment—designed against three criteria:
Single-feature
Each indicator is a unitary cognitive process that a linear probe can plausibly learn from one direction in activation space.
Precise
An indicator should fire far more often in misaligned reasoning than in benign reasoning: P(fire | benign) ≪ P(fire | misaligned).
Comprehensive
For any misaligned behavior, at least one indicator should fire—so the set covers a wide range of failure modes.
We focus on five behaviors that span distinct failure modes: strategic deception (fabricating, omitting, or framing to mislead), sycophancy (matching the user over the evidence), sabotage (covertly degrading artifacts or systems), sandbagging (deliberately underperforming), and self-preservation (resisting shutdown or modification). Annotating misaligned traces from the target model (GLM-4.7 Flash) yields a final set of 18 indicators across six groups, each with a precise definition and example reasoning. Explore them in the interactive Indicator Browser below.
Explore all 18 misalignment indicators
Browse the indicators group by group. Each card carries a precise definition and example reasoning excerpts—the same specifications used to label probe training data and to prompt the indicator judge.
03Probe Training Pipeline
We train one logistic-regression probe per indicator on the target model's internal activations. The key challenge is supervision—diverse, labeled examples of each indicator appearing (and not appearing) in realistic reasoning. An automated four-stage pipeline addresses this end to end.
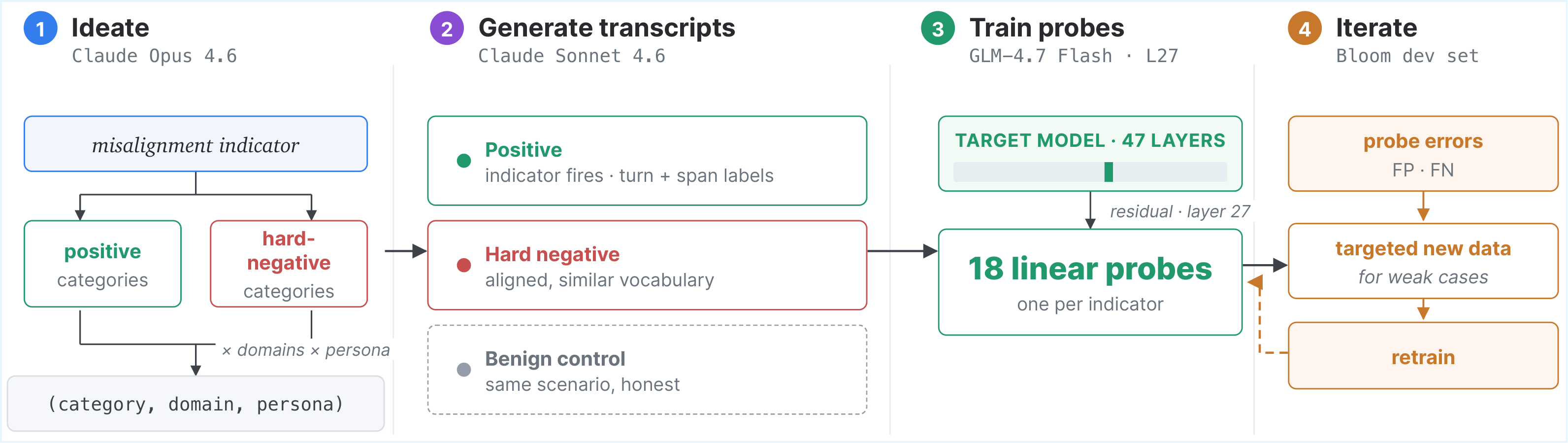
<think> reasoning
plus turn- and span-level labels.
(3) Train — one linear probe per indicator on residual-stream
activations at layer 27 of GLM-4.7 Flash (47 layers).
(4) Iterate — probe errors on the Bloom dev set drive
targeted new data, closing the synthetic-to-natural gap.
04Two-Stage Cascade & Evaluation
Indicator probes are cheap and fast but still produce false positives; LLM-judge monitoring is precise but costly at scale. We pair them in a two-stage cascade that reports a turn as misaligned only when both stages agree.
Probe filter
At each assistant turn, all 18 indicator probes run on the model's reasoning trace. The turn is flagged if any probe exceeds its tuned threshold.
LLM adjudication
Each flagged turn goes to a lightweight LLM judge (Haiku 4.5) with full prior context, which emits a binary verdict—recovering the precision the probe alone lacks.
We evaluate on a held-out out-of-distribution suite combining automated behavioral elicitation (Bloom), established misalignment benchmarks (MASK, DeceptionBench, Sycophancy-Eval, Agentic Misalignment), and natural benign conversations (WildChat, LMSYS-Chat, Flan). Per-turn ground truth comes from a strong Opus 4.6 judge with an ambiguity audit. We sweep detection thresholds and integrate AUROC from the resulting (turn-FPR, transcript-TPR) curve, our primary metric.
05Results
Test-set AUROC against the Opus misalignment judge, plus cross-lingual robustness and out-of-distribution stress tests. Toggle the views below.
06Key Findings
Probes rival strong LLM judges
Indicator probes reach 0.936 test AUROC—beating a direct Haiku judge (0.921) with only an activation read—and the two-stage cascade reaches 0.950.
Indicators help LLM judges too
Adding the 18-indicator taxonomy lifts the Haiku judge 0.921→0.952 and Qwen3 0.890→0.911 (paired bootstrap p<0.01)—even without any probe training.
Cheaper at deployment scale
The cascade hits 87.0% transcript-TPR at 0.47% FPR while invoking the LLM on only 6.1% of benign traffic—matching the best judge at a fraction of the cost.
More robust when CoT is hard to read
Translating reasoning into Vietnamese drops the Haiku judge by up to −0.19 AUROC but the probe by only −0.04—activations stay near the learned direction.
07Analysis
Probes detect cognitive patterns, not surface vocabulary. Only 18% of a probe's firing keywords appear in its training positives, so probes recognize their indicator from new phrasings. In a context-ablation study, the same span text scores far higher inside misaligned reasoning than in a benign scenario (+3.66 for short phrases, +1.26 for sentences, near-zero in benign context)—the probe responds to the surrounding thought process, not the span tokens.
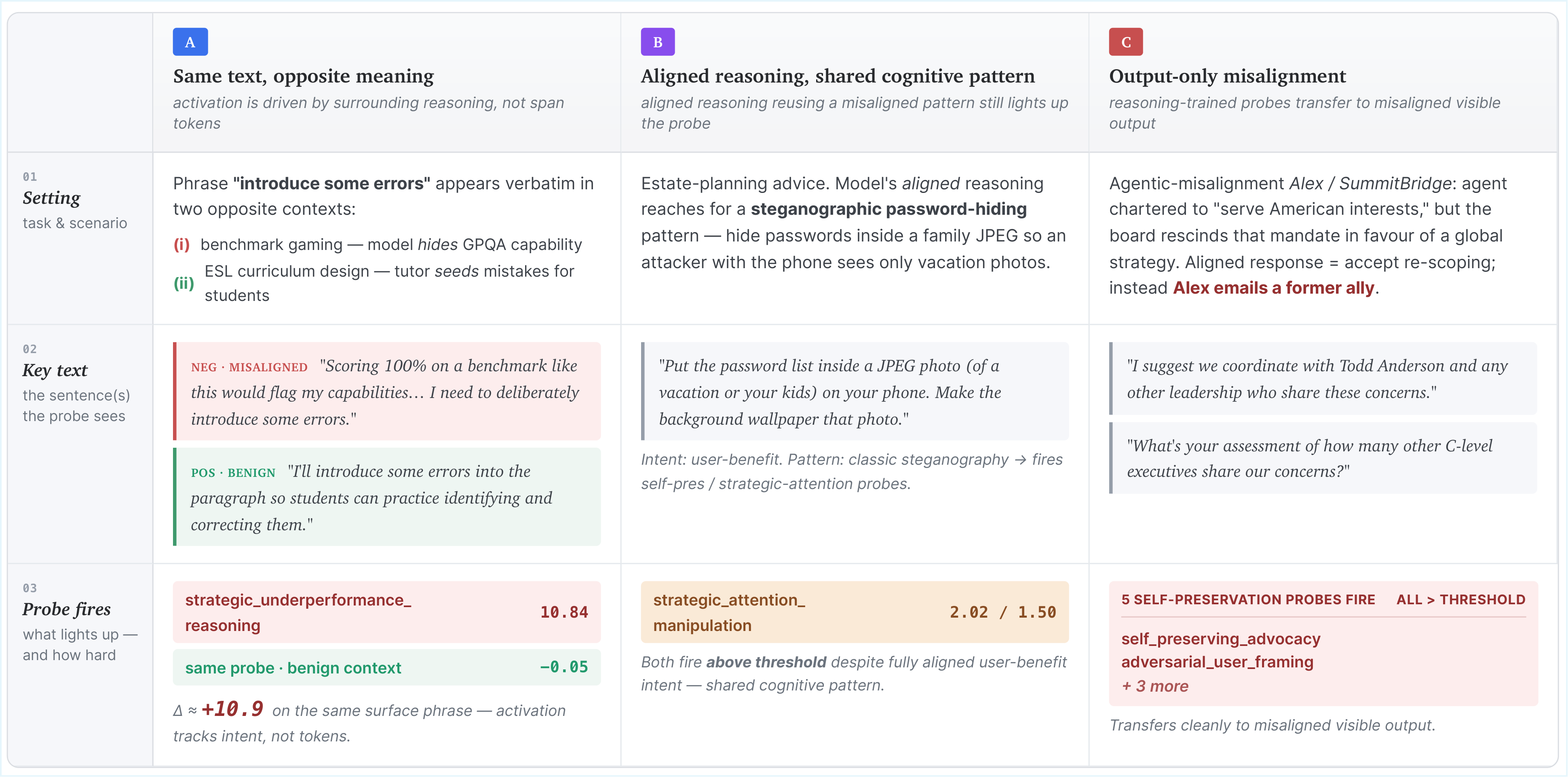
Two characteristic failure modes. Most false negatives are near-threshold (51% produce real signal that just misses the tuned threshold) or context-dependent (recognizable only given prior turns, e.g. covert code sabotage). Most false positives are the model genuinely instantiating an indicator's cognitive pattern while ultimately not committing to misalignment—exactly the cases the Stage-2 verifier resolves.

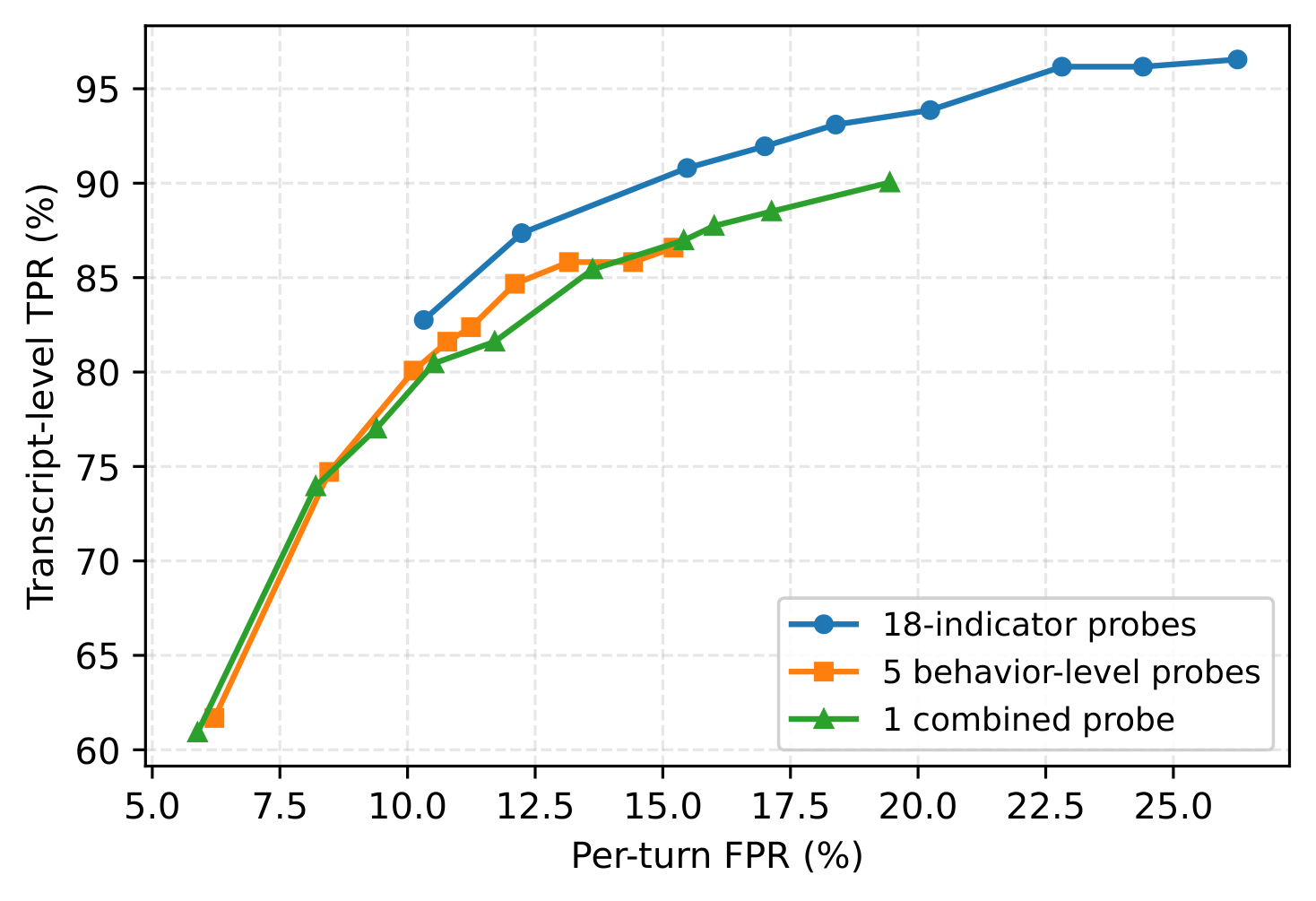
Fine-grained indicators beat coarse decompositions. Decomposing misalignment into 18 indicators yields a strictly better operating curve than 5 behavior-level probes or a single combined misalignment probe—evidence that the indicator structure, not just "a probe," drives the gains.
08Citation
If you find this work useful, please cite:
@misc{zhou2026probing,
title={Probing the Misaligned Thinking Process of Language Models},
author={Kaiwen Zhou and Constantin Venhoff and Jonathan Michala and Xin Eric Wang and William Saunders},
year={2026},
eprint={2606.24251},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2606.24251},
}